
Statisticians love to analyze numbers, but what do they do when what they want to explore is unformatted text? It happens all the time. The text may come from open -ended responses on surveys, social networking sites, email, online reviews, public comments, notations (e.g., medical, customer relations), documents and text files, or even recorded and transcribed interactions. But before anything can happen, you have to accomplish three tasks:
-ended responses on surveys, social networking sites, email, online reviews, public comments, notations (e.g., medical, customer relations), documents and text files, or even recorded and transcribed interactions. But before anything can happen, you have to accomplish three tasks:
- Get the text into a spreadsheet or other software that you can use to manipulate it.
- Break the text into analyzable fragments – letters, words, phrases, sentences, paragraphs, or whatever.
- Assign properties to the text fragments
How you might complete these tasks depends on what you want to do and the software you have. Nonetheless, you’ll be surprised by how much you can do with just a spreadsheet and an internet connection if you have the time and focus. This article will show you how.
Approaches
Ther e are several ways that you can analyze text. You can:
e are several ways that you can analyze text. You can:
- Count the occurrence of specific letters, words, or phrases, often summarized as Word Clouds. There are quite a few free web sites that will help you construct word clouds.
- Categorize text by key themes, topics, or commonalities, called Text Mining.
- Classify attitudes, emotions, and opinions of a source toward some topic, called Sentiment Analysis or opinion mining. There are many applications of sentiment analysis in business, marketing, customer management, political science, law, sociology, psychology, and communications.
- Explore relationships between words using a Word Net. The relationships can reflect definitions or other commonalities.
Some of these analyses can be performed using free web apps, others, require special software.
Specialized Software
Some text analytics can be performed manually, but it is a time consuming process so having software can be crucial. Unfortunately, the biggest and best software is proprietary, like SAS and SPSS, and costs a lot. There are also free and low-cost alternatives, as well as free web sites that preform less sophisticated analyses. There are a lot of software options so there are probably a lot of people analyzing text. Let Google be your guide.
Manual Analyses
Even if you don’t have access to specialized software for text analyses, you can also still perform two types of analyses with nothing more than a spreadsheet program and an internet connection. You can count the number of times that a letter, word, or phrase appears in a text passage. Word frequency turns out to be relatively easy to produce but once you have the counts, the analysis and interpretation may be a bit more challenging. You can also do simple topic analyses or sentiment analyses. Parsing the sentences or sentence fragments and analyzing them is straightforward but time consuming, though the interpretation is usually easier.
Word Counts
If you are just looking for keywords or counting words for some diagnostic purpose, you’ll find that it’s not that difficult. Here’s how to do word counts.
Step 1 – Find the text you want to analyze.
This is usually easy except for there being so many choices. You have to start with an electronic file. If you have hard copy, you’ll have to sc
an it and correct the errors. If you have text from separate sources, you’ ll want to aggregate them to make things easier. If you have text on a website, you can usually highlight it and copy it using <ctrl-C>. If the passage is long, you can use <ctrl-A> to select everything before copying it, but you’ll have to edit out the extraneous material. You can do these operations in most word processors.
ll want to aggregate them to make things easier. If you have text on a website, you can usually highlight it and copy it using <ctrl-C>. If the passage is long, you can use <ctrl-A> to select everything before copying it, but you’ll have to edit out the extraneous material. You can do these operations in most word processors.
Step 2 – Scrub the data
You should scrub the text to be sure you’ll be counting the correct things. Take out entries that aren’t part of the flow of the text, like footnotes and section numbers. Correct misspellings. Take out punctuation that might become associated with words, like em dashes.
Step 3 – Count the words.
The quickest way to count words is to go to an Internet site for that purpose. Just copy your scrubbed text, paste it into the box on the site, and press submit. You’ll get a column of words and their frequencies. Parse the numbers from the text and you’re ready to analyze the data. It’s a good idea to review the results of the counting to be sure no errors have crept into the process.
Another way to do this solely in a spreadsheet is to replace all the punctuation with blanks and then replace the blanks with paragraph marks. This will give you a column of words. Copy it and remove the duplicates then you can use a formula to count each word.
Once you have the counts, the analysis is up to you. You can compare word statistics from different sources or analyze word frequencies within a single source. The possibilities are endless. Interpretation is another matter. Here are some examples.
One thing you can do with word counts is to produce a word cloud. There are many web sites that will generate these graphics. My favorite is Wordle, but be advised, you have to use Internet Explorer for it to work. Here’s an example of a word cloud produced with Wordle.

Text Mining
Topic or Sentiment Analyses are straightforward but more time consuming than word counts. Unless you are analyzing text for work or school, relax and turn on Netflix. This isn’t very sophisticated, but it’ll take a while and you’ll need frequent breaks to maintain your focus.
There are six steps.
Step 1 – Get the Data into a Spreadsheet
As with word counts, you have to get the text file into a text manager, preferably a spreadsheet. Highlight your text or use <ctrl A> and then <ctrl C> and <ctrl V>. You’ll need to parse any block text into sentences or whatever length fragment you want to analyze. You can usually do this by replacing periods with paragraph marks. Start with a small dataset, perhaps fewer than fifty fragments, until you get used to the process.
Step 2 – Scrub the Responses
Format the fragments into a single column with one fragment per row. Delete extraneous fragments. Don’t worry about misspellings and punctuation. If you make a mistake, <ctrl Z> will undo it.
Step 3 – Assign Descriptors
In a column next to the column with the fragments, enter your first descriptor. It can be a keyword, theme, sentiment, length, or whatever you want to analyze. Unless you have predetermined descriptors you are looking for, don’t worry too much about the descriptors you use. You’ll review and edit them in the next step.
 Step 4 – Count the Fragments Assigned to Each Descriptor
Step 4 – Count the Fragments Assigned to Each Descriptor
When you count the fragments assigned to each descriptor, you’ll probably find a few descriptors with only a few fragments. Consider combining them with other descriptors. When you’re satisfied with the assignments, you might want to subdivide the descriptor groups with another set of descriptors.
Step 5 – Repeat Steps 3 and 4
You can repeat the last two steps as many times as you feel is necessary. You can use these hierarchical descriptor groups to characterize subsets of the text so don’t have too many or too few fragments in each descriptor group. When you’re done, your data set would look something like this.
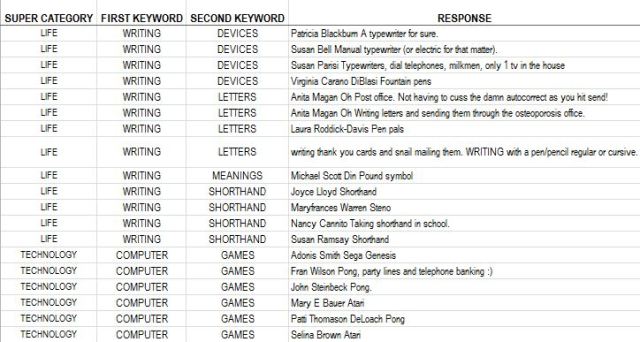
If you have a predetermined set of descriptors, you can assign each one to a column of the spreadsheet and code them as 0 or 1 for presence or absence.
Step 6 – Analyze
Once you have built your data set, you can analyze it statistically by counts and percentages, or graphically using word clouds. Consider this example. On December 29, 2016, Tanya Lynn Dee asked the question on her Facebook page, “Without revealing your actual age, what [is] something you remember that if you told a younger person they wouldn’t understand?” There were over 1,000 responses (at the time I saw the post), which I copied and classified into common themes. The results are here.
To learn more about analyzing text for its sentiment, read Sentiment Analysis
nearly everything you need to know by MonkeyLearn.
So, try analyzing some text (and other things) at home. You won’t need parental supervision.

Read more about using statistics at the Stats with Cats blog. Join other fans at the Stats with Cats Facebook group and the Stats with Cats Facebook page. Order Stats with Cats: The Domesticated Guide to Statistics, Models, Graphs, and Other Breeds of Data analysis at amazon.com, barnesandnoble.com, or other online booksellers.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
Pingback: How to Analyze Text | A bunch of data
Pingback: This Week in Data Science (February 21, 2017) – Be Analytics
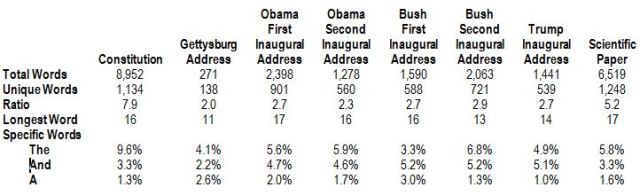
Here’s an example of a major text analysis.
Click to access 119370.full.pdf
Very interesting!
Terminology
http://www.datasciencecentral.com/profiles/blogs/10-common-nlp-terms-explained-for-the-text-analysis-novice?utm_content=buffercab35&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
Another good example of text analysis and classification: https://www.bisok.com/data-science-workbench/text-classification/