Statistics isn’t a new thing. It dates back at least fifty centuries beginning as counts in the form of tally marks for keeping track of crops, animals, people, and time. From there, it evolved with the demands of government and business, supported by academic inquiry and the growth of technology.
The Era of Prehistoric Statistics
Statistics began with the simple act of counting. It sounds unremarkable today. Humans learn to do it in childhood. Even some animals can do it. But thousands of years ago, it was momentous. There was no precedent for it. The concept was unheard-of; there was no process to follow. Then came tally marks as both a tool to count and to remember counts.
As counting became more sophisticated in the ancient world, tally marks evolved into symbols. Those symbols evolved into numbers. Numbering systems were then created to allow for bigger numbers by using place values where the position of a digit determines its value.
Sumerians and later Babylonians had numbering systems around the 30th century BC. Roman numerals appeared in the 9th century BC while Egyptian and Greek numbering systems arose in the 4th and 5th centuries BC. Hindu-Arabic numerals originated in India in the 6th or 7th century and were introduced in Europe in the 12th century by Leonardo Pisano (aka Fibonacci), an Italian mathematician.
Ancient rulers used these numbering systems to perform censuses of their citizenry and inventories of their crops. Early scholars even used statistical principles to perform rudimentary calculations for solving real-world problems. No doubt, the governments also used numbers to administer taxes.
The Era of Emerging Statistics
Early developments of number systems laid the groundwork for the evolution of statistics and probability as distinct fields of study. Still, before the 16th Century, ideas about numbers were more philosophical than mathematical. The notable exception came in the mid-1500s when Italian mathematician Gerolamo Cardano calculated the probabilities of dice throws.
Statistics became established in society by the mid-1600s when governments began tabulating their resources and economies beyond just making a census of their citizenry. John Graunt made statistical inferences from public health data. Most notably, Blaise Pascal and Pierre de Fermat established the mathematical foundation for probability. In the 1700s, Reverend Thomas Bayes introduced the conception of probability that evolved into Bayesian statistics.
The 18th and 19th centuries were when the fundamental concepts and the mathematical underpinnings of statistics were developed.
The Era of Blooming Statistics
The 1800s began with French mathematician Adrien-Marie Legendre describing the method of least squares in a book about calculations in astronomy. He used least-squares as a way to weigh errors. German mathematician Carl Friedrich Gauss claimed to have developed the method a decade earlier. He had used it in his work developing the Normal distribution, which may have been discovered sixty years earlier by French mathematician Abraham de Moivre.
English nexialist Sir Francis Galtondevelopedfoundational concepts involving correlation and regression while working in genetics. His student, Karl Pearson, further developed his ideas. The Pearson product-moment correlation coefficient was named after him for his efforts.
Sir Ronald Fisher was dubbed the father of modern statistics for his work on the analysis-of-variance (ANOVA) and the statistical design of experiments. William Sealy Gosset pioneered small-sample experimental design under the pseudonym Student including the development of the t-distribution and test of statistical significance.
Even with all the advancements, or maybe because of them, cynics railed against “lies, damn lies, and statistics.” A few decades earlier, Pearson had also pointed out that “correlation does not imply causation.” Nonetheless, advances made during the 19th century secured probability and statistics as a rigorous mathematical discipline.
By the early 1900s, statistical analysis were being integrated in a wide variety of scientific disciplines as well as in industry and government.
The Era of Mature Statistics
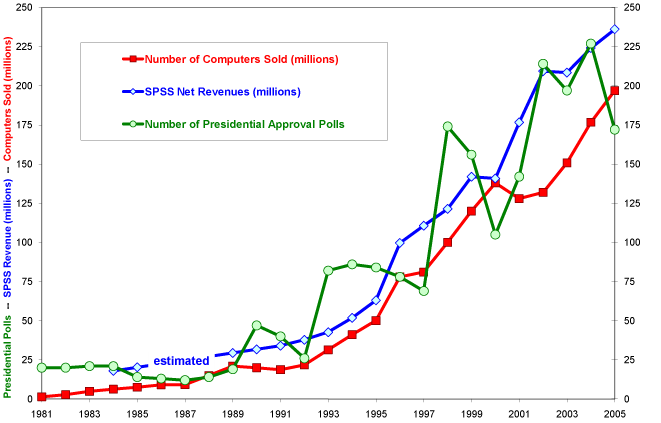
The mature era of statistics began in the 1940s when World War II brought an explosion of technology. Statisticians played their part in war efforts, benefiting greatly from the recognition, but the biggest boost for statistics came with the introduction of programmable computers. The government led the way in analyzing data, both census and business data, with their new computer resources. Universities, pollsters, and businesses followed. Suddenly, numbers were everywhere. Every aspect of American life was enhanced by statistics. Nine out of ten doctors said so.
Then in 1954, Darrell Huff published “How to Lie with Statistics,” perhaps as an admonition against believing the results of statistical analyses without careful consideration. It is ironic that Huff, a journalist with no formal training in statistics, would later testify before Congress in the 1950s and the 1960s against the statistical relationship between cigarette smoking and lung disease.
Nevertheless, Huff’s book became a best-selling book on statistics. It sold over a million copies in English by the 2000s and has been translated into over twenty languages. It has also spawned numerous books and articles echoing the same theme of caution in consuming information involving numbers. Unfortunately, many people take these books (or just their titles) to mean that all presentations that use statistics are dishonest. This unfounded belief has returned statistics to the false notoriety it suffered from over a century before.
The Era of Pervasive Statistics
After the end of World War II, the popularity of statistics was poised to explode again. The dinosaur mainframes were replaced by hordes of small personal computers with user-friendly (by comparison) statistical software and programming languages.
The rise of business use of statistics led to the ascendency of data science, the melding of statistics with data engineering, programming, and domain expertise. It was thought by some to be a necessity in the age of computers, internet communications, big data, and high-stakes decision making with profit motives. The creation of Amazon in 1994 ultimately led to an expansive use of statistics and artificial intelligence (AI) to increase sales, a trend that has spread to many other consumer businesses.
Academia also played a part in the rebirth of statistics after the 1950s. Statistics began to be a requirement for more and more degrees outside of STEM, including some degrees in history, archaeology, geography, agriculture, journalism, graphic communications, library science, culinary science, and linguistics.
One repercussion of academia’s new focus on statistics has been that more people consider themselves to be competent in statistics after learning just a few concepts and formulas in HS. Some consider themselves to be experts after taking Stats 101. While not being expert enough to conduct an analysis of their own, they still consider themselves to be knowledgeable enough to argue using numbers on social media. That’s still better than opinionated arm-waving or hearing lies, damn lies, and statistics all the time, though. Right?
At the same time that statistics was evolving into a bigger, more complex discipline, an even bigger revolution grew in mass communications.
Technology. The internet evolved from a secure communications system for military researchers in the 1960s to a consumer necessity in the 1990s. Satellites and wireless technologies are now spreading capabilities for communication everywhere.
Telephony. Wireless phones first appeared in the 1970s and evolved into smartphones by the 1990s. Mobile phones became as popular as landlines in the 2000s, creating issues with statistical surveys because the demographics of the owners were different. By the 2010s, more people owned wireless phones than landlines. Not many people rely exclusively on landlines anymore.
Messaging. Instant messaging began in the 1970s and has evolved and expanded since. Bulletin Boards Systems (BBSs) were popular in the 1980s and 1990s. Internet Relay Chat (IRC) began in the 1990s and is still being used. Audio podcasts date back to the 1980s but didn’t achieve much popularity until the 2000s. Text blogging began in the 1980s and expanded into video blogging in the 2000s. YouTube appeared in 2005.
Social Media. Social media began in the 1990s with GeoCities, Classmates, and SixDegrees. In the 2000s, Friendster and Myspace appeared only to be overtaken by Facebook in 2004 and Twitter in 2006. Two decades later, there are too many platforms to mention.
Books. Numbers differ, but there are from a half million to four million book titles published every year. eBooks represent only a fraction of that amount but while the growth of hardcopy book publishing is static, ebook publishing is increasing exponentially. eBook technologies have been around since the 1930s but didn’t become popular until the 2000s. By 2010, Amazon was selling more ebooks than hardcopy books. Amazon currently holds over 60 thousand titles related to statistics, including over 2,000 introductory statistics titles, over 3,000 college statistics titles, and over 500 high school statistics titles.
Business. A critical change in how we receive news began in the 1970s when the major outlets decided to require their news divisions to be profitable. ABC led the way with non-traditional news programming, like 20/20 and Nightline, and other networks followed. The aim to be profitable pressured news outlets to sacrifice quality for quicker news releases. In the 1980s, all three major networks were bought by larger corporations, which increased demands for higher profits.
Government. Two major changes in Federal regulations transformed how information was made available to the public. From 1949 until 1987, the Fairness Doctrine required licensed radio and television broadcasters to devote some airtime to discussing controversial matters of public interest and to air contrasting views on those matters. The Telecommunications Act of 1996 increased the number of television stations that a single company could own, which led to a major consolidation of media outlets. Before the Act, fifty companies controlled the media in America; by 2011, only six did. These policies had the effect of limiting which news stories were presented and how they were framed. At the same time, smaller information providers multiplied on the internet giving people greater latitude in picking their sources of information. Not all of those new information outlets provided the same level of veracity, however. Who told them?
Society. There has always been gossip, rumors, unverified reports, propaganda, and other falsehoods passed from person-to-person in society. But today, mass communications has magnified the availability of those falsehoods leading to the proliferation of fake news in the media. The number of websites and podcasts spreading fake news increases every day with little regulation. There are even sites for generating fake news articles and memes, alternative facts, and spurious correlations. Sometimes it’s difficult to distinguish between what is real information, what is satire and parody, and what is fake. This makes understanding and trusting statistics, and all of science in general, all the more difficult.
All of these changes happened in about forty years. Depending on when you were born, you may not even recognize how life worked before these advancements. Certainly, they have had an enormous impact on how the science of statistics is being presented in the media. This is why it is essential to become an informed consumer of statistical information.
Read more about the fundamentals of statistics in Chapter 1 of Stats with Kittens.